
实时交易量系统如何精准捕捉市场动态并辅助决策?
 摘要:
系统核心概念系统架构与工作流程关键技术栈前端展示界面(核心部分)后端逻辑(伪代码示例)挑战与优化方向系统核心概念实时交易量系统,顾名思义,核心是“实时”和“交易量”,交易量: 指在...
摘要:
系统核心概念系统架构与工作流程关键技术栈前端展示界面(核心部分)后端逻辑(伪代码示例)挑战与优化方向系统核心概念实时交易量系统,顾名思义,核心是“实时”和“交易量”,交易量: 指在... - 系统核心概念
- 系统架构与工作流程
- 关键技术栈
- 前端展示界面(核心部分)
- 后端逻辑(伪代码示例)
- 挑战与优化方向
系统核心概念
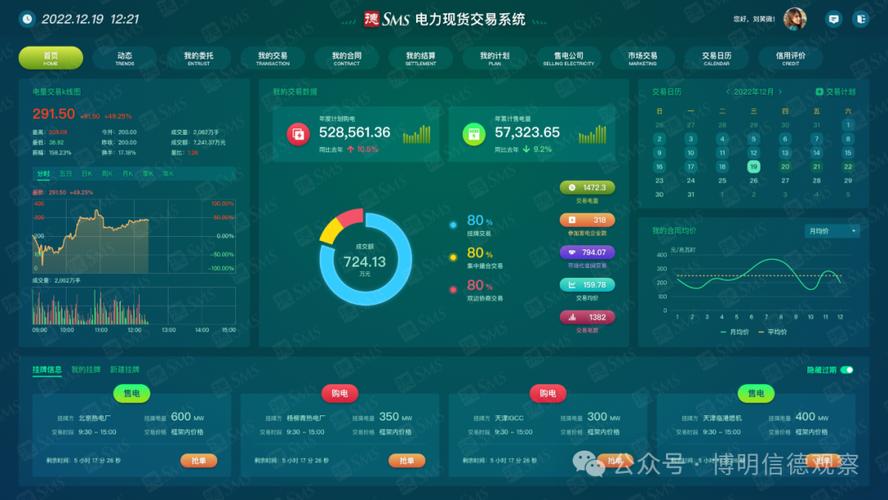
实时交易量系统,顾名思义,核心是“实时”和“交易量”。
- 交易量: 指在特定时间窗口内(如1秒、1分钟)完成的交易笔数或交易金额,它反映了市场的活跃度和资金的流动情况。
- 实时: 指数据的采集、处理和展示之间的延迟极低,通常是秒级甚至毫秒级,用户看到的数据几乎就是当前市场的即时情况。
核心目标:
(图片来源网络,侵删)
- 监控: 实时观察市场或特定资产的交易热度。
- 分析: 发现交易模式的异常,例如突然放量可能预示着重大新闻或市场情绪变化。
- 决策: 为交易员、分析师或量化策略提供及时的数据支持。
系统架构与工作流程
一个典型的实时交易量系统采用分层架构,确保高可用、低延迟和高吞吐量。
工作流程如下:
-
数据源:
- 交易所API: 如 Binance, Coinbase, OKX 等提供的 WebSocket 或 RESTful API,WebSocket 是首选,因为它能实现服务器主动推送数据,延迟最低。
- 数据供应商: 如 Kaiko, CryptoCompare 等提供的历史和实时数据流。
- 内部数据: 公司内部的订单簿、成交记录等。
-
数据采集层:
 (图片来源网络,侵删)
(图片来源网络,侵删)- 任务: 建立与数据源的稳定连接,订阅交易数据流。
- 组件: 运行多个数据采集服务,每个服务负责连接一个或多个数据源,使用 WebSocket 客户端库来接收实时消息。
-
数据处理与计算层:
- 任务: 这是系统的核心,它负责接收原始数据,进行清洗、格式化,并实时计算各种交易量指标。
- 组件:
- 消息队列: 如 Kafka, RabbitMQ,作为数据缓冲区,解耦数据采集和处理模块,即使处理层暂时宕机,数据也不会丢失。
- 流处理引擎: 如 Apache Flink, Spark Streaming,这是计算的大脑,它消费消息队列中的数据,进行窗口聚合计算。
-
数据存储层:
- 任务: 存储原始数据和计算后的聚合结果,用于历史查询、回测和监控。
- 组件:
- 时序数据库: 如 InfluxDB, TimescaleDB,专为时间序列数据设计,读写性能极高,非常适合存储交易量这类带时间戳的数据。
- NoSQL数据库: 如 Redis,用于存储热点数据(如当前热门交易对),利用其内存特性和高性能。
- 数据湖: 如 Hadoop HDFS,用于存储海量原始数据,用于长期分析和机器学习。
-
数据服务层:
- 任务: 为前端应用提供数据接口。
- 组件: 提供 RESTful API 或 WebSocket 接口,前端通过这些接口订阅实时数据推送或查询历史数据。
-
应用展示层:
 (图片来源网络,侵删)
(图片来源网络,侵删)- 任务: 将数据以直观、友好的方式呈现给用户。
- 组件: Web 前端、移动端 App、数据大屏等。
关键技术栈
| 层次 | 技术(示例) |
|---|---|
| 数据源 | Binance/Coinbase WebSocket API, Kaiko Stream API |
| 数据采集 | Python (aiohttp, websockets), Go (goroutines), Node.js |
| 消息队列 | Apache Kafka (高吞吐、持久化), RabbitMQ (灵活路由) |
| 流处理 | Apache Flink (事件时间处理、状态管理), Spark Streaming |
| 数据存储 | InfluxDB (时序数据), Redis (缓存/排行榜), PostgreSQL (关系数据) |
| 数据服务 | WebSocket (实时推送), RESTful API (历史查询) |
| 前端框架 | Vue.js / React (构建UI), ECharts / D3.js (图表库), Socket.io (WebSocket客户端) |
| 部署 | Docker, Kubernetes (K8s) |
前端展示界面(核心部分)
这是用户直接交互的地方,设计必须清晰、直观、响应迅速。
界面布局示例
假设我们监控的是加密货币市场。
核心功能模块:
-
实时交易量指标卡
- 总交易量 (24h):
$125.8B(带百分比变化,如+2.3%) - 当前TPS (Transactions Per Second):
1,250(每秒交易笔数) - 热门交易对榜: 实时滚动显示交易量最大的前5个交易对。
- 总交易量 (24h):
-
实时交易量图表
- 类型: 折线图或面积图。
- X轴: 时间(秒级或分钟级)。
- Y轴: 交易量(可以是交易笔数或交易金额)。
- 交互:
- 可以选择不同时间窗口(如1分钟、5分钟、15分钟、1小时)。
- 鼠标悬停显示具体时间点的精确数值。
- 图表必须平滑、无卡顿地实时更新。
-
交易对详情看板
- 当用户点击某个交易对(如
BTC/USDT)时,下方展开详情。 - 该对实时交易量图表: 专门展示
BTC/USDT的交易量变化。 - 订单簿深度图: 展示当前买卖挂单情况,与交易量结合分析。
- 最近成交记录: 实时滚动的成交列表,显示价格、数量和时间。
- 当用户点击某个交易对(如
-
实时事件流
- 一个侧边栏,显示“异常”事件。
- 示例:
[警告] BTC/USDT 在过去5秒内交易量突增300%,这需要后端设定阈值并触发告警。
技术实现 (前端伪代码)
// 使用 ECharts 和 Socket.io
// 1. 初始化图表
const myChart = echarts.init(document.getElementById('volume-chart'));
// 2. 定义图表配置
const option = { { text: '实时交易量' },
tooltip: { trigger: 'axis' },
xAxis: {
type: 'time',
splitLine: { show: false }
},
yAxis: {
type: 'value',
name: '交易量 (BTC)'
},
series: [{
name: '交易量',
type: 'line',
data: [], // 初始为空
smooth: true,
areaStyle: {}
}]
};
myChart.setOption(option);
// 3. 通过 WebSocket 连接后端服务
const socket = io('ws://your-backend-server');
// 4. 监听实时数据推送
socket.on('trade-volume-update', (data) => {
// data 格式: { timestamp: '2025-10-27T10:00:05Z', volume: 15.8 }
// 获取当前数据
const currentData = myChart.getOption().series[0].data;
// 添加新数据点
currentData.push([data.timestamp, data.volume]);
// 保持数据点数量,例如只显示最近60个点
if (currentData.length > 60) {
currentData.shift();
}
// 更新图表,使用 'none' 避免动画卡顿
myChart.setOption({
series: [{ data: currentData }]
}, true); // 第二个参数 'true' 表示不合并,直接替换
});
后端逻辑(伪代码示例)
后端的核心是计算,我们以 Flink 为例,展示如何计算每秒的交易量。
// 伪代码: Apache Flink Job
// 1. 定义数据源(从 Kafka 读取原始交易数据)
DataStream<Trade> tradeStream = env
.addSource(new FlinkKafkaConsumer<>("raw-trades", new TradeDeserializer(), properties));
// 2. 定义窗口,按每秒进行分组聚合
// 使用事件时间,并允许1秒的延迟
KeyedStream<Trade, String> keyedStream = tradeStream
.assignTimestampsAndWatermarks(WatermarkStrategy.<Trade>forBoundedOutOfOrderness(Duration.ofSeconds(1))
.withTimestampAssigner((event, timestamp) -> event.getTimestamp()));
// 3. 执行聚合计算
DataStream<VolumeMetric> volumeMetrics = keyedStream
.window(TumblingEventTimeWindows.of(Time.seconds(1))) // 滚动窗口,每秒一个
.aggregate(new VolumeAggregator()); // 自定义聚合器
// 4. 将结果写入 InfluxDB 和发送到 WebSocket
volumeMetrics.addSink(new InfluxDBSink()); // 写入时序数据库
volumeMetrics.addSink(new WebSocketSink()); // 推送给前端
// --- 自定义聚合器 VolumeAggregator ---
public class VolumeAggregator implements AggregateFunction<Trade, VolumeAccumulator, VolumeMetric> {
@Override
public VolumeAccumulator createAccumulator() {
return new VolumeAccumulator(); // 初始化累加器
}
@Override
public VolumeAccumulator add(Trade trade, VolumeAccumulator acc) {
acc.count++; // 交易笔数 +1
acc.amount = acc.amount.add(trade.getAmount()); // 交易金额累加
return acc;
}
@Override
public VolumeMetric getResult(VolumeAccumulator acc) {
return new VolumeMetric(acc.pair, acc.count, acc.amount, acc.windowEnd);
}
@Override
public VolumeAccumulator merge(VolumeAccumulator a, VolumeAccumulator b) {
// 用于会话窗口,此处省略
return a;
}
}
挑战与优化方向
构建一个稳定、高效的实时交易量系统面临诸多挑战:
-
低延迟: 市场瞬息万变,毫秒级的延迟都可能导致决策失误。
- 优化: 使用高性能语言(如 Go, Rust)、网络优化(如零拷贝)、将流处理任务部署在靠近数据源的区域。
-
高吞吐: 交易数据量巨大,尤其是在牛市或某个币种暴涨时。
- 优化: 水平扩展流处理任务、使用 Kafka 分区、优化聚合算法。
-
数据一致性: 如何处理乱序事件?一个10:00:05的交易因为网络延迟在10:00:06才到达。
- 优化: Flink 的“事件时间”和“水位线”机制就是为了解决这个问题,可以设置一个允许的最大延迟时间,晚于此时间的数据将被丢弃。
-
系统稳定性: 7x24小时不间断运行。
- 优化: 服务容器化、自动扩缩容、完善的监控和告警体系(如 Prometheus + Grafana)。
-
可扩展性: 如何轻松地增加新的交易对或新的计算指标?
- 优化: 采用微服务架构,将数据采集、处理、服务解耦,使用配置中心动态管理计算任务。
通过以上展示,您应该对“实时交易量系统”有了从宏观架构到微观实现的全面了解,它是一个融合了数据工程、实时计算和前端可视化的复杂而有趣的系统。
文章版权及转载声明
作者:咔咔本文地址:https://jits.cn/content/23499.html发布于 01-17
文章转载或复制请以超链接形式并注明出处杰思科技・AI 股讯
还没有评论,来说两句吧...