
区块链数据存储大小
 摘要:
核心观点区块链的数据存储大小是持续、指数级增长的, 这是因为区块链的本质是一个不断追加的、不可篡改的分布式账本,每一个新区块被打包进来,整个链的数据大小就会增加,下面我们从几个主要...
摘要:
核心观点区块链的数据存储大小是持续、指数级增长的, 这是因为区块链的本质是一个不断追加的、不可篡改的分布式账本,每一个新区块被打包进来,整个链的数据大小就会增加,下面我们从几个主要... 核心观点
区块链的数据存储大小是持续、指数级增长的。 这是因为区块链的本质是一个不断追加的、不可篡改的分布式账本,每一个新区块被打包进来,整个链的数据大小就会增加。
下面我们从几个主要维度来详细拆解这个问题。
主流公链的数据大小现状(截至2025年中)
为了有一个直观的感受,我们先看看几个主流公链的当前数据大小:
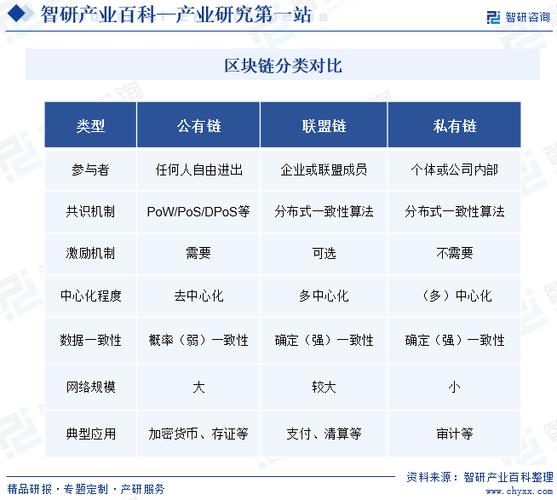
| 区块链名称 | 大致数据大小 (估算) | 特点 |
|---|---|---|
| 比特币 | ~ 550 GB | 数据增长相对缓慢,以UTXO模型和简洁的脚本著称。 |
| 以太坊 | ~ 1.2 TB | 数据增长速度远超比特币,因为智能合约和复杂的交易逻辑存储了更多状态数据。 |
| Solana | ~ 1.5 TB | 以高性能著称,但数据同步和存储压力巨大,是全节点运行的主要挑战之一。 |
| 狗狗币 | ~ 500 GB | 代码和结构与比特币类似,所以数据大小也相近。 |
| 比特币现金 | ~ 300 GB | 区块大小比比特币大,但历史较短,所以总数据量目前更小。 |
| Polygon PoS | ~ 400 GB | 作为以太坊的Layer 2,其数据大小独立于以太坊主网,但仍需存储大量交易和状态数据。 |
注意: 这些数字每天都在增长,并且会因同步的起始时间、是否包含归档数据等因素而有所不同。
影响区块链数据大小的关键因素
为什么不同区块链的数据大小差异如此之大?主要由以下几个因素决定:
a) 区块大小与出块间隔
这是最直观的因素。
-
区块大小: 指每个区块能容纳多少交易数据,区块越大,相同时间内产生的数据就越多。
- 比特币: 区块大小上限最初为1MB,后通过隔离见证等技术扩展到约4MB,增长非常保守。
- 以太坊: 没有固定的区块大小上限,但有“燃气费”机制,由市场供需决定每个区块能容纳多少交易,随着DeFi、NFT的兴起,区块大小经常波动。
- BCH / BSV: 故意设计出巨大的区块(目前为32MB甚至更大),旨在成为“世界账本”,数据增长速度非常快。
-
出块间隔: 指产生一个新区块需要的时间。
- 比特币: 约10分钟,意味着数据是缓慢、稳定地写入。
- 以太坊: 约12-15秒,出块频率是比特币的80倍,意味着数据写入速度快得多。
- Solana: 约0.4-0.8秒,极高的出块频率带来了巨大的数据吞吐量,存储压力也呈指数级增长。
简单公式:数据增长速度 ≈ 区块大小 × 出块频率
b) 数据存储模型
区块链不仅存储交易,还需要存储状态,这导致了不同的数据膨胀。
-
账户模型
- 代表: 以太坊
- 工作原理: 类似于银行账户,记录每个账户的余额、代码、存储等状态,为了验证一个账户的当前状态,可能需要追溯到它创建时的所有历史交易。
- 数据特点: 状态数据(State Data)占比很高,且会随着网络活动(如智能合约部署、NFT铸造)而膨胀,这是以太坊数据量巨大的主要原因。
-
UTXO (Unspent Transaction Output) 模型
- 代表: 比特币
- 工作原理: 将交易记录为“花费”和“创造”未花费的输出,每个UTXO都是一个独立的、可被花费的“金币”。
- 数据特点: 主要存储交易数据本身,状态数据相对精简,验证一个UTXO是否有效,只需查询该UTXO是否存在,历史追溯性较弱,因此数据更加“简洁”。
c) 智能合约与DApp活动
智能合约的复杂性是数据膨胀的“催化剂”。
- 复杂的合约逻辑: 合约代码越长,部署时占用的存储空间就越大。
- 频繁的状态更新: DeFi协议中的价格预言机更新、NFT的转移、游戏内的资产变动等,都会频繁地写入链上状态,导致状态数据爆炸式增长。
- 日志: 合约产生的所有事件日志都会被永久记录,这也是数据的重要组成部分。
d) 共识机制
不同的共识机制对数据同步和存储有不同要求。
- PoW (工作量证明): 如比特币,节点需要从创世区块开始,逐个验证所有区块,这个过程耗时耗力(数天到数周),但验证逻辑相对简单。
- PoS (权益证明): 如以太坊,节点也需要同步完整数据,但验证机制不同,PoS的验证者节点需要有极高的同步速度,否则可能错过验证机会而被惩罚,这对存储设备的I/O性能要求更高。
数据大小带来的挑战与解决方案
巨大的数据量给区块链生态系统带来了严峻的挑战,也催生了一系列创新解决方案。
挑战
- 节点运行门槛高: 存储数TB的数据需要昂贵的硬盘(通常需要高性能SSD)和稳定的网络环境,这使得普通用户几乎无法运行全节点,威胁了网络的去中心化。
- 网络同步困难: 新节点加入网络时,需要下载并验证所有历史数据,这个过程可能需要数周甚至更长时间,严重影响新用户的参与体验。
- 中心化风险: 节点运行成本高昂,可能导致节点集中在少数大型机构(如交易所、云服务商)手中,形成事实上的中心化。
- 数据孤岛: 历史数据可能因为被遗忘而无法访问,影响链上应用的完整性。
解决方案
-
分层架构
- Layer 1 (L1): 基础链,通过协议层面的优化来减少数据增长,如比特币的隔离见证、以太坊的EIP-4844(Proto-Danksharding)。
- Layer 2 (L2): 在L1之上构建的扩展方案,将大量计算和数据存储放在链下处理,只将最终结果或证明提交到L1,这是目前最主流的扩展方向。
- Rollups (Optimistic & ZK): 如Arbitrum, Optimism, zkSync, StarkNet,它们极大地减少了主链的数据负担。
-
数据可用性层
专门负责存储和保证区块链数据可用性的独立层,Celestia 和 EigenDA,它们为L2提供数据可用性服务,进一步解耦了数据存储和共识。
-
归档节点 vs. 全节点
- 全节点: 存储所有区块头和所有状态数据,可以独立验证任何交易,这是保证去中心化的核心。
- 归档节点: 存储所有历史数据,包括所有状态和交易的完整历史,可以查询任何历史时刻的状态,但硬件要求极高。
- 精简节点: 只存储区块头,通过查询其他全节点来获取特定状态的数据,它不存储完整状态,大大节省了空间,但牺牲了一定的去中心化验证能力。
-
状态租赁 / 状态过期
一些新兴的区块链设计提出,可以为链上状态数据设定一个“租赁期”或“过期时间”,超过期限的状态数据可以被“修剪”(Pruned),即从大多数节点上删除,只留下证明其历史存在性的数据,这能显著控制数据量的无限增长。
区块链数据存储大小是一个动态且复杂的问题,它是由出块频率、区块大小、数据模型和生态活动共同决定的。
- 比特币因其保守的设计,数据增长相对可控,但依然达到了数百GB。
- 以太坊等智能合约平台则因为复杂的账户模型和繁荣的DApp生态,数据量更为庞大,成为数据扩展的“重灾区”。
- Solana等高性能链则在追求速度的同时,也面临着巨大的数据存储挑战。
为了应对这一挑战,分层架构(尤其是Layer 2) 和 数据可用性层 已经成为行业公认的未来方向,它们通过将数据压力从主链转移出去,有望在保障去中心化的同时,支撑起更大规模的全球应用,对于普通用户和开发者而言,理解数据大小的意义,有助于更好地选择合适的工具和平台参与区块链世界。
作者:咔咔本文地址:https://jits.cn/content/24410.html发布于 01-26
文章转载或复制请以超链接形式并注明出处杰思科技・AI 股讯
还没有评论,来说两句吧...