
实时人气排行榜如何实时更新?数据来源是否真实可靠?排名波动背后有何影响因素?
 摘要:
下面我将从核心概念、实现方式、技术挑战、应用场景和示例等多个维度,为您全面解析“实时人气排行榜”, 核心概念:什么是实时人气排行榜?实时人气排行榜是一个动态更新的列表,它根据预设的...
摘要:
下面我将从核心概念、实现方式、技术挑战、应用场景和示例等多个维度,为您全面解析“实时人气排行榜”, 核心概念:什么是实时人气排行榜?实时人气排行榜是一个动态更新的列表,它根据预设的... 下面我将从核心概念、实现方式、技术挑战、应用场景和示例等多个维度,为您全面解析“实时人气排行榜”。
核心概念:什么是实时人气排行榜?
实时人气排行榜是一个动态更新的列表,它根据预设的人气指标(如点赞数、观看人数、购买量、投票数等),对特定对象(如商品、主播、选手、帖子)进行实时排序。
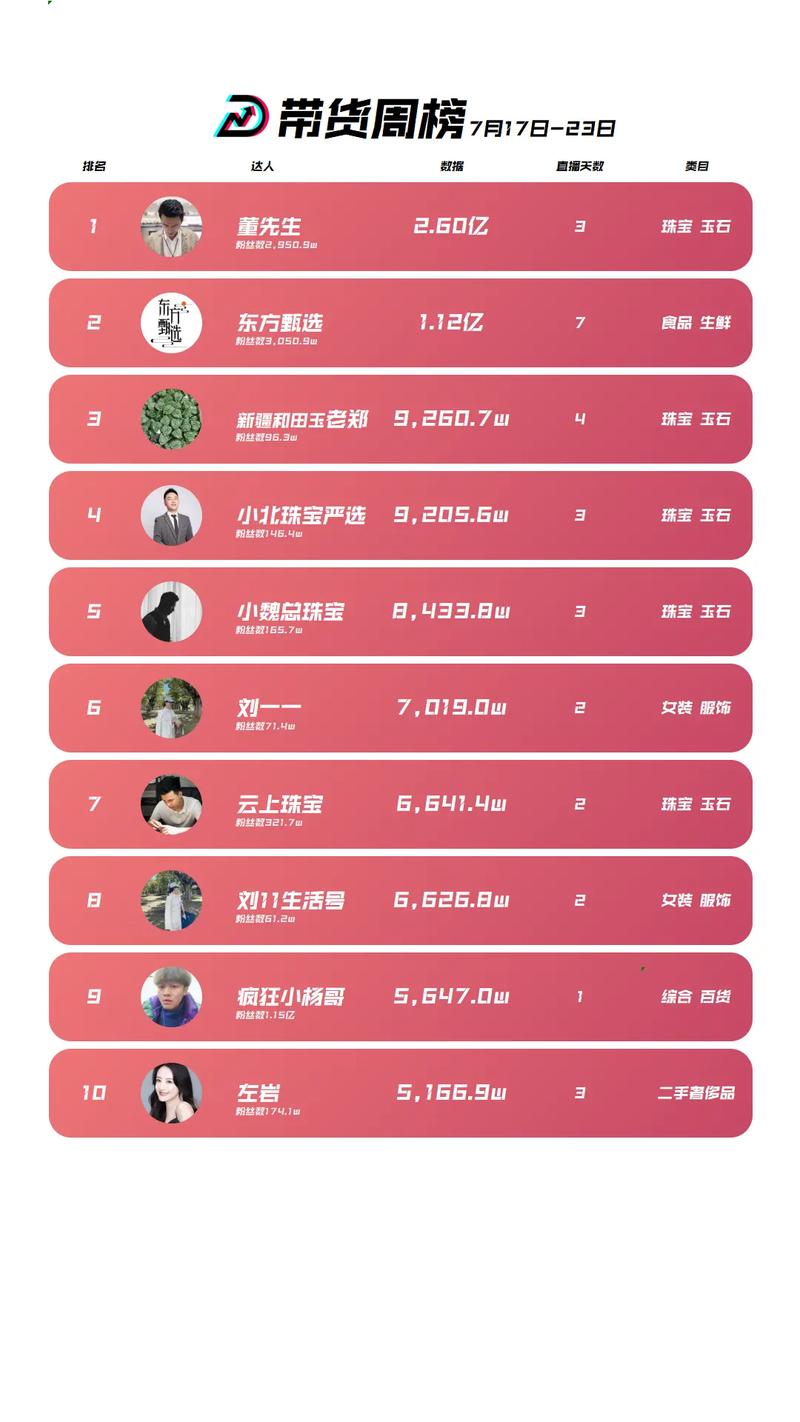
(图片来源网络,侵删)
核心要素:
- 对象: 排行榜排名的实体,商品ID、主播昵称、选手编号。
- 指标: 衡量人气的数据。
点赞数、观看人数、销售额、新增粉丝数。 - 时间窗口: “实时”是一个相对概念,排行榜的统计时间范围可以是:
- 当前时刻: 纯粹的瞬时值(如当前在线人数)。
- 最近N分钟/小时: 最近1小时人气榜”。
- 本周/本月: 今日销量榜”。
- 排序规则: 根据指标值从高到低(或从低到高)排序。
- 更新频率: 排行榜刷新的频率,如每10秒、每分钟更新一次。
实现方式与技术架构
要实现一个高性能的实时排行榜,关键在于如何高效地处理源源不断的数据并快速排序,以下是几种主流的技术实现方案,从简单到复杂排列。
数据库排序 (适用于低并发、低实时性要求)
这是最直接的方式,但不推荐用于高并发的“实时”场景。
- 实现逻辑:
- 每次有新的数据(如一个赞)到来时,直接更新数据库中对应记录的
like_count字段。 - 当需要展示排行榜时,查询数据库,按
like_countDESC 排序,并取前N名。
- 每次有新的数据(如一个赞)到来时,直接更新数据库中对应记录的
- 优点:
实现简单,逻辑清晰。
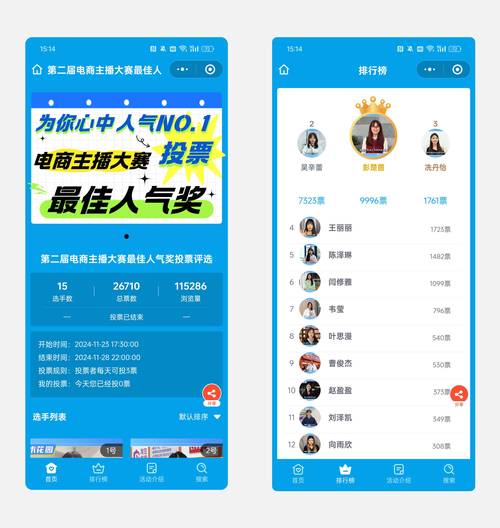 (图片来源网络,侵删)
(图片来源网络,侵删) - 缺点:
- 性能瓶颈: 每次更新都写数据库,高并发下数据库压力巨大。
- 排序延迟: 复杂的排序查询(尤其是大数据量时)非常耗时,无法做到“实时”更新。
- 适用场景: 小型应用、后台管理统计、非核心业务。
内存计算 + 定时排序 (主流方案)
这是目前最常用、性价比最高的方案,通过牺牲少量“最终一致性”来换取高性能和高实时性。
- 核心思想: 将排行榜的计算从数据库转移到内存中。
- 技术栈:
- 数据结构: 有序集合,Redis 中的
ZSET(Sorted Set) 或 Elasticsearch 中的Sorted类型,它们天然支持高效的插入、更新和范围查询(Top N)。 - 工作流程:
- 数据写入: 用户行为(点赞、购买等)产生事件,被发送到消息队列(如 Kafka, RabbitMQ)。
- 实时更新: 消费者从消息队列中读取事件,实时更新内存中的有序集合,一个赞的事件,就执行
ZSET.INCR user_id操作,这个操作是 O(log N) 复杂度,速度极快。 - 定时任务: 一个后台定时任务(如每分钟执行一次)负责将内存中的排行榜数据持久化到数据库,并可能做一些更复杂的聚合计算。
- 数据读取: 前端请求排行榜时,直接从内存中的有序集合读取
ZSET.RANK和ZSET.REVRANGE,获取最新的排名和Top N列表。
- 数据结构: 有序集合,Redis 中的
- 优点:
- 高性能: 内存操作速度远超数据库,能轻松应对高并发。
- 高实时性: 排行榜可以做到秒级甚至毫秒级更新。
- 可扩展: 可以通过增加消费者实例来水平扩展处理能力。
- 缺点:
- 数据一致性: 内存和数据库之间可能存在短暂的不一致,但通常对于排行榜业务,这种延迟是可以接受的。
- 适用场景: 绝大多数需要实时排行榜的业务,如直播、电商、游戏。
流处理引擎 (最高级方案)
适用于对实时性、计算复杂度要求极高的场景。
- 核心思想: 采用专业的流处理框架(如 Flink, Spark Streaming)进行实时计算。
- 技术栈:
- 数据源: Kafka。
- 计算引擎: Apache Flink / Spark Streaming。
- 存储: Redis (用于实时结果) + HBase/ClickHouse (用于历史数据)。
- 工作流程:
- 用户行为事件进入 Kafka。
- Flink 消费 Kafka 中的数据流,进行实时窗口计算(如每5秒的滑动窗口)。
- Flink 将计算出的每个时间窗口的排行榜结果,实时写入 Redis。
- 前端直接从 Redis 读取排行榜。
- 优点:
- 极致的实时性: 毫秒级延迟。
- 强大的计算能力: 支持复杂的实时聚合、关联、去重等计算。
- Exactly-Once 语义: 可以保证计算结果的精确性。
- 缺点:
- 架构复杂: 需要搭建和维护一套完整的流处理技术栈,成本高。
- 开发门槛高: 需要专业的流处理工程师。
- 适用场景: 大型互联网公司、金融风控、复杂实时数据分析。
面临的挑战与解决方案
-
数据倾斜问题
- 挑战: 少数头部对象(如顶流明星、爆款商品)的数据量巨大,导致单个处理节点负载过高。
- 解决方案:
- 分片: 将排行榜按维度(如商品类别、主播分区)进行分片,每个分片独立计算排名。
- 异步处理: 对头部对象的数据进行特殊处理,如异步落盘,避免阻塞主流程。
-
缓存穿透与击穿
 (图片来源网络,侵删)
(图片来源网络,侵删)- 挑战: 大量请求直接打到排行榜的缓存(Redis)上,如果缓存失效(击穿)或查询不存在的数据(穿透),会直接压垮数据库。
- 解决方案:
- 缓存预热: 系统启动时或活动开始前,将排行榜数据加载到缓存。
- 布隆过滤器: 在查询缓存前,先通过布隆过滤器快速判断数据是否存在。
- 互斥锁: 缓存失效时,只允许一个线程去加载数据,其他线程等待。
- 设置合理的过期时间: 并使用随机过期时间,避免集体失效。
-
实时性与一致性的权衡
- 挑战: 100%的实时和100%的一致性在分布式系统中往往无法同时满足。
- 解决方案: 明确业务需求,对于排行榜,通常接受“最终一致性”,即允许有几十秒到几分钟的延迟,保证系统的高可用和高性能。
应用场景示例
| 场景 | 排行对象 | 人气指标 | 时间窗口 | 技术选型 |
|---|---|---|---|---|
| 直播平台 | 主播 | 当前观看人数、礼物收益 | 当前时刻/今日 | 方案二 (Redis ZSET) |
| 电商平台 | 商品 | 销售额、订单数、收藏数 | 实时/历史 | 方案二 (Redis ZSET + 定时任务) |
| 社交媒体 | 话题/帖子 | 点赞数、转发数、评论数 | 24小时/本周 | 方案二 (Redis ZSET) |
| 在线游戏 | 玩家/公会 | 战力值、活跃度、击杀数 | 当前赛季/本周 | 方案二 (内存计算) |
| 选秀/投票活动 | 选手/候选人 | 得票数 | 活动期间/实时 | 方案二 (Redis ZSET) |
| 新闻资讯 | 文章/视频 | 阅读量、互动量 | 实时 | 方案二 (Redis ZSET) |
一个简单的直播人气榜实现示例 (伪代码)
技术栈: Node.js + Redis + Socket.io
Redis 数据结构: 使用一个 ZSET 来存储主播的人气值。
- Key:
live_ranking - Member:
主播ID(如anchor_123) - Score:
当前人气值(如5)
核心逻辑代码:
// 引入Redis客户端
const redis = require("redis");
const io = require("socket.io")(server);
// 创建Redis客户端
const client = redis.createClient();
// 模拟用户进入直播间
function userJoinRoom(anchorId, userId) {
// 1. 更新该主播的在线人数 (这里简化,实际可能用Hash存储详细人数)
// HINCRBY live:anchor:anchor_123 online_users 1
// 2. 更新排行榜 (增加人气值)
client.zincrby("live_ranking", 1, anchorId, (err, reply) => {
if (err) console.error(err);
// 3. 广播排行榜更新
updateAndBroadcastRanking();
});
}
// 模拟用户发送礼物
function userSendGift(anchorId, giftValue) {
// 礼物价值直接加到人气值上
client.zincrby("live_ranking", giftValue, anchorId, (err, reply) => {
if (err) console.error(err);
// 广播排行榜更新
updateAndBroadcastRanking();
});
}
// 获取并广播排行榜
function updateAndBroadcastRanking() {
// 从ZSET中获取排名最高的10位主播
// ZREVRANGE live_ranking 0 9 WITHSCORES
client.zrevrange("live_ranking", 0, 9, "WITHSCORES", (err, ranking) => {
if (err) {
console.error(err);
return;
}
// 将结果格式化为前端需要的JSON
const topAnchors = [];
for (let i = 0; i < ranking.length; i += 2) {
topAnchors.push({
anchorId: ranking[i],
popularity: ranking[i+1]
});
}
// 通过WebSocket广播给所有连接的客户端
io.emit("ranking_update", topAnchors);
});
}
// 设置一个定时任务,定期将内存数据持久化到数据库(可选)
// setInterval(() => { ... }, 60000); // 每分钟执行一次
// 监听WebSocket连接
io.on("connection", (socket) => {
console.log("User connected:", socket.id);
// 可以在这里处理用户加入/离开事件
});
// 启动服务器
server.listen(3000, () => {
console.log("Server is running on port 3000");
});
这个例子清晰地展示了如何利用 Redis 的 ZINCRBY 和 ZREVRANGE 命令,高效地实现一个实时人气排行榜的更新和查询。
希望这份详细的解析能帮助您全面了解“实时人气排行榜”!
文章版权及转载声明
作者:咔咔本文地址:https://jits.cn/content/26945.html发布于 今天
文章转载或复制请以超链接形式并注明出处杰思科技・AI 股讯
还没有评论,来说两句吧...