
非实时HTTP服务数据返回时,如何优化延迟与数据一致性?
 摘要:
什么是非实时HTTP服务数据返回?就是客户端发起一个HTTP请求后,服务器不立即返回最终的计算结果,而是立即返回一个任务受理的凭证,客户端可以拿着这个凭证去查询任务的状态,直到任务...
摘要:
什么是非实时HTTP服务数据返回?就是客户端发起一个HTTP请求后,服务器不立即返回最终的计算结果,而是立即返回一个任务受理的凭证,客户端可以拿着这个凭证去查询任务的状态,直到任务... 什么是非实时HTTP服务数据返回?
就是客户端发起一个HTTP请求后,服务器不立即返回最终的计算结果,而是立即返回一个任务受理的凭证,客户端可以拿着这个凭证去查询任务的状态,直到任务完成后再获取最终结果。
这就像在餐厅点餐:
(图片来源网络,侵删)
- 实时模式(同步):你点完菜,厨师必须在你座位上当场把菜炒好端给你,你才能离开,如果厨师炒菜需要1小时,你就必须等1小时。
- 非实时模式(异步):你点完菜,服务员给你一个取餐号(任务凭证),然后你就可以先去逛街、看电影(去做别的事),过一会,你可以通过屏幕或广播查询你的餐号是否做好了(轮询),或者等服务员叫号(回调/通知),菜好了,你再去取。
在Web开发中,非实时模式就是为了解决“厨师炒菜时间太长”的问题。
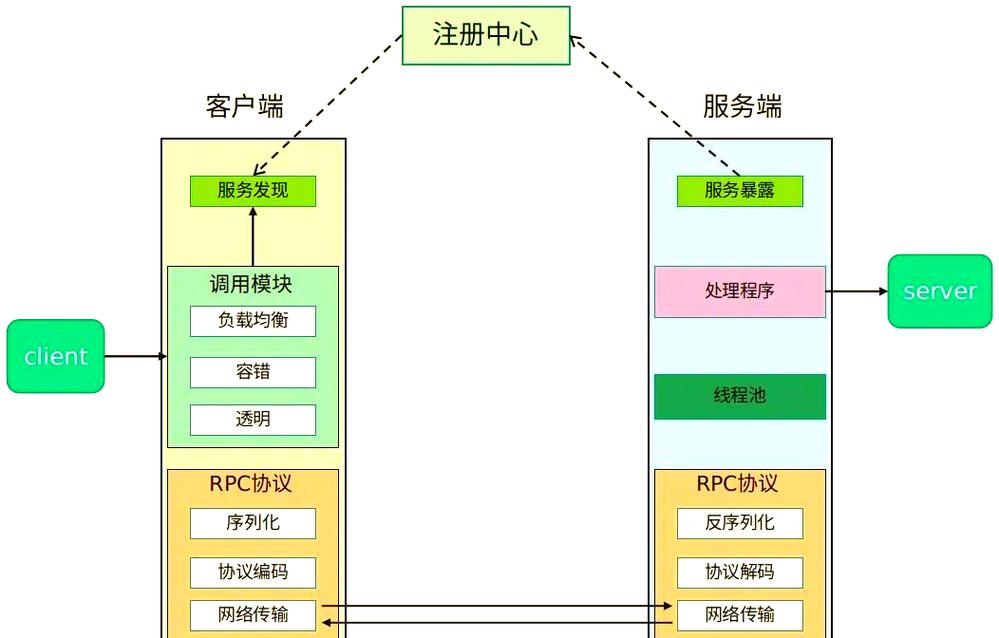
核心工作流程
一个典型的非实时HTTP服务流程如下:
-
客户端提交任务:
- 客户端向服务器的某个API端点(
/api/tasks)发送一个HTTPPOST请求。 - 请求体中包含处理该任务所需的所有数据(一个大型视频文件、一个复杂的计算参数等)。
- 客户端向服务器的某个API端点(
-
服务器受理任务:
 (图片来源网络,侵删)
(图片来源网络,侵删)- 服务器接收到请求后,不立即开始执行耗时操作。
- 它将任务信息(如任务ID、参数、状态等)存入一个任务队列(如RabbitMQ, Kafka, Redis List)或数据库。
- 服务器立即响应一个HTTP
202 Accepted状态码。 - 响应体中包含一个任务ID(Task ID),这是客户端后续查询的唯一凭证。
HTTP/1.1 202 Accepted Content-Type: application/json { "task_id": "a1b2c3d4-e5f6-7890-abcd-ef1234567890", "message": "Task has been accepted and is being processed.", "status_url": "https://api.example.com/api/tasks/a1b2c3d4-e5f6-7890-abcd-ef1234567890/status" } -
后台任务处理:
- 服务器有一个或多个后台工作进程(Worker)。
- 这些Worker持续不断地从任务队列中获取新任务。
- 获取任务后,Worker执行耗时的计算、文件处理、API调用等操作。
- 任务处理过程中,Worker可能会更新任务的状态(从 "PENDING" -> "PROCESSING" -> "SUCCESS" / "FAILED")。
-
客户端查询状态:
- 客户端收到
202 Accepted响应后,知道任务已经被接受。 - 客户端可以使用响应体中的
status_url,通过HTTPGET请求来轮询任务的状态。
GET /api/tasks/a1b2c3d4-e5f6-7890-abcd-ef1234567890/status HTTP/1.1
- 服务器根据任务ID查询当前状态并返回。
// 任务处理中 HTTP/1.1 200 OK { "task_id": "a1b2c3d4-e5f6-7890-abcd-ef1234567890", "status": "PROCESSING", "progress": 50, // 可选,显示进度 "created_at": "2025-10-27T10:00:00Z" } // 任务完成 HTTP/1.1 200 OK { "task_id": "a1b2c3d4-e5f6-7890-abcd-ef1234567890", "status": "SUCCESS", "result_url": "https://api.example.com/api/tasks/a1b2c3d4-e5f6-7890-abcd-ef1234567890/result", "created_at": "2025-10-27T10:00:00Z", "finished_at": "2025-10-27T10:05:00Z" } // 任务失败 HTTP/1.1 200 OK { "task_id": "a1b2c3d4-e5f6-7890-abcd-ef1234567890", "status": "FAILED", "error": "Input file format is not supported.", "created_at": "2025-10-27T10:00:00Z", "finished_at": "2025-10-27T10:01:00Z" } - 客户端收到
-
获取最终结果:
- 当客户端通过轮询得知任务状态为 "SUCCESS" 后,可以再次请求
result_url来获取最终的数据。
GET /api/tasks/a1b2c3d4-e5f6-7890-abcd-ef1234567890/result HTTP/1.1
服务器返回处理完成的数据,例如一个JSON对象、一个文件下载链接等。
 (图片来源网络,侵删)
(图片来源网络,侵删) - 当客户端通过轮询得知任务状态为 "SUCCESS" 后,可以再次请求
实现技术栈
- 后端框架:
- Python: Flask + Celery / RQ (Redis Queue) / Django with Celery
- Node.js: Express.js + BullMQ (with Redis) / Bee-Queue
- Java: Spring Boot + Spring Integration / Quartz
- Go: Gin + Asynq (with Redis) / custom workers
- 消息队列/任务队列:
- Redis: 最常用,轻量级,速度快,适合大多数场景,RQ, Celery, BullMQ等都支持。
- RabbitMQ: 功能强大,支持复杂的路由和确认机制,企业级应用常用。
- Kafka: 高吞吐量,适用于日志处理、事件流等大数据场景。
- 数据库: 也可以直接用数据库表作为队列,但性能和可靠性不如专业消息队列。
- Worker:
通常是一个独立于Web服务器的进程或服务,负责从队列中拉取并执行任务。
优缺点
优点
- 提升用户体验:用户不用在页面上干等,可以继续浏览其他内容,系统会通知他任务何时完成。
- 提高系统吞吐量:Web服务器(如Nginx, Gunicorn)可以快速释放连接去处理新的请求,而不是被一个耗时任务阻塞,Worker可以独立扩展,处理能力更强。
- 增强系统健壮性:如果Web服务器重启,已经进入队列的任务通常不会丢失(取决于队列的持久化配置),而正在处理的同步任务则会中断。
- 实现更复杂的业务逻辑:可以轻松实现任务重试、超时控制、任务链、任务分组等高级功能。
缺点
- 架构更复杂:需要引入任务队列、Worker等组件,系统设计和维护成本更高。
- 延迟:从提交任务到获取结果,总时间会比同步模式长,因为多了一个查询和等待的过程。
- 客户端逻辑更复杂:客户端需要实现轮询逻辑,并处理各种状态(等待、处理中、成功、失败)。
- 资源消耗:需要额外的资源来运行Worker和消息队列服务。
最佳实践与注意事项
- 提供任务状态查询接口:务必提供一个稳定、高效的
status接口。 - 设置合理的超时:为任务设置一个超时时间,防止任务卡住。
- 实现任务重试机制:对于因瞬时故障(如网络抖动)失败的任务,应有自动重试的机制。
- 任务幂等性:确保同一个任务被多次执行(Worker重启后重新拉取)不会产生副作用,通常通过任务ID来保证。
- 结果存储与清理:任务完成后,其结果(特别是大文件)需要妥善存储,并设置过期时间自动清理,避免存储空间无限增长。
- 安全性:
status_url和result_url中的ID应该是不可预测的,避免用户通过遍历ID来获取他人的任务结果。 - WebSocket 通知(可选优化):对于需要实时通知的场景,可以在任务完成时通过WebSocket向特定客户端推送消息,而不是让客户端一直轮询,这能进一步减少不必要的请求。
非实时HTTP服务数据返回是构建高可用、高性能后端服务的标准模式之一,它通过将耗时任务异步化,有效解决了同步请求的瓶颈问题,极大地提升了系统的整体表现和用户体验,虽然它增加了系统的复杂性,但对于任何需要处理长时间运行任务的应用来说,这都是一个值得投入的架构选择。
文章版权及转载声明
作者:咔咔本文地址:https://jits.cn/content/33292.html发布于 今天
文章转载或复制请以超链接形式并注明出处杰思科技・AI 股讯
还没有评论,来说两句吧...